About
Can we program computers in our native tongue? This idea, termed natural language programming, has attracted attention almost since the inception of computers themselves. From the point of view of software engineering (SE), efforts to program in natural language (NL) have relied thus far on controlled natural languages (CNL) – small unambiguous fragments of English. Yet, CNLs are very restricted and their expression is artificial. Is it possible to replace CNL with truly natural, human language?
From the point of view of natural language processing (NLP), current technology successfully extracts static information from NL texts. However, human-like NL understanding goes far beyond such extraction – it requires dynamic interpretation processes which affect, and is affected by, the environment, update states and lead to action. So, is it possible to endow computers with this kind of dynamic NL understanding?
The ambitious, cross-disciplinary, goal of this project is to induce ``NL compilers’’ that are able to accept a natural language description as input and map it to an executable system. These compilers will continuously acquire NL understanding (NLU) capacity via learning from signals involving verification, simulation, synthesis or user feedback. Such NL compilers will have vast applications in AI, SE, robotics and cognitive computing, and will fundamentally change the way humans and computers interact.
Team
Everyone say 'Hi' :-)

PI: Dr. Reut Tsarfaty
Head of the ONLP lab. Interested in natural language programming, morphological, syntactic and semantic parsing. Recipient of ERC-StG Grant #677352 and an ISF grant #1739/26

Dr. Victoria Basmova
Postdoc.

Dr. Royi Lachmy
Educational Data Scientist and ONLP lab postdoc interested in bringing the NLP cutting-edge research for the advance of the Science and Mathematics Education research. Researching semantic parsers for context-related programming in natural language as part of developing educational apps aimed at nurturing student Computational Thinking skills.

Tzuf Argaman
PhD Candidate at Ber-Ilan University. Researching grounded and executable semantic parsing, zero-shot learning and multimodality.
Projects

Representation:
The Empty Elements Project
Empty elements are elements left out by the speaker and inferred by the hearer. They are central to obtaining human-like language understanding. Some examples of empty elements are:
- Fused heads: I bought three apples and ate two [apples].
- Verb-phrase ellipsis: John bought books, Jane didn’t [buy books].
- Aspectual verb constructions: I finished [reading? writing?] the book.
- Bridging: I love these shoes. The color [of the shoes] is beautiful!.
In this project we investigate Empty Elements Expansion (EEE), a challenge wherein we aim to automatically recognize and resolve such empty elements in texts.
Bridging, for example, is a (non-identity) implicit relation between two nouns in the text. For example in the sentence “I entered the room. The ceiling was high” there is an implicit part-whole relation between “the ceiling” and “the room”, yielding the “complete” expression “the ceiling [of the room]”. How can we collect data concerning those missing elements? How can we design learning models to infer them? How can these empty elements aid Natural Language Understanding applications, and in particular, Natural Language Programming?
For more detail about bridging and the data collection interface, check out our introduction and qualification tests and our annotation tool.

Models:
Natural Language Navigation
Following navigation instructions in natural language requires a composition of language, action, and knowledge of the environment. Knowledge of the environment may be provided via visual sensors or as a symbolic world representation referred to as a map. This project aims at learning to ground objects using multimodal world knowledge. This project has been selected this year (2020) to receive funds from Google Faculty Research Award.
For materials, data sets and models, follow us.
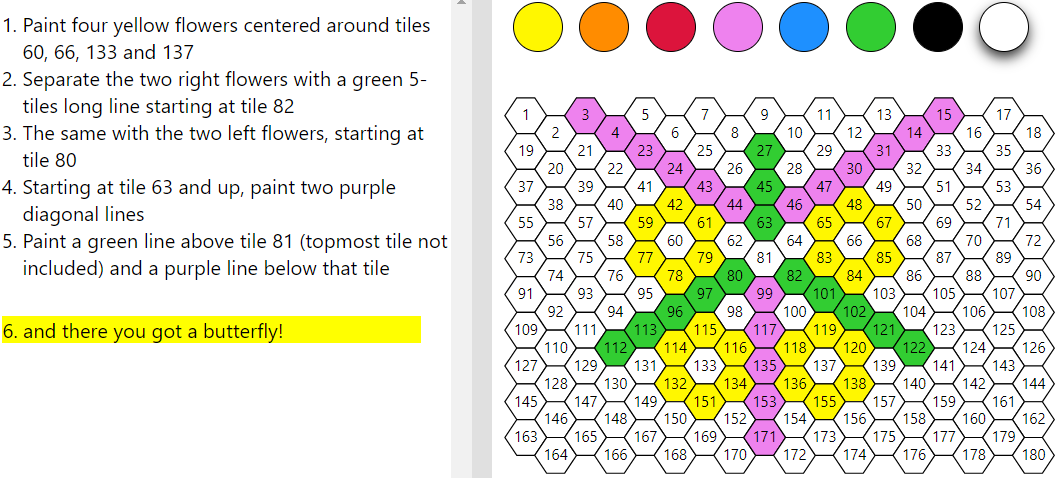
Applications:
NLPRO-CT: Nurturing Computational Thinking Skills with Natural Language Programming
In the NLPRO-CT we develop and use NLPRO semantic parsers to build accessible educational apps that enhance young students’ Computational Thinking (CT) skills.
The Hexagon Board App is our first app being developed in this framework. In this conversational app users verbally instruct the automatic painter how to draw their desired image on a kids board game paved with hexagonal tiles. To reach that goal we created two complementary apps to collect the initial dataset required to train our model. The dataset is comprised of corresponding pairs of images and drawing procedure. The first version is used to create those pairs whereas the second one is used to ensure the quality of those pairs.
Read about and experiment with both apps:
Introduction & Hexagon Board App 1
Introduction & Hexagon Board App 2
Take part in our project and contribute new and interesting images to our dataset.
Publications
Peer-reviewed articles
Paz-Argrman, Tzuf; Tsarfaty, Reut RUN through the Streets: A New Dataset and Baseline Models for Realistic Urban Navigation. EMNLP 2019
Tsarfaty, Reut; Seker, Amit; Sadde, Shoval; Klein, Stav. What's Wrong with Hebrew NLP? And How to Make it Right. EMNLP 2019 Demo Paper
More, Amir; Seker, Amit; Basmova, Victoria; Tsarfaty, Reut. Joint Transition-Based Models for Morpho-Syntactic Parsing: Parsing Strategies for MRLs and a Case Study from Modern Hebrew. Transactions of the Association for Computational Linguistics 7. Pages 33-48, 2019. MIT Press One Rogers Street, Cambridge, MA 02142-1209 USA
Sadde, Shoval; Seker, Amit; Tsarfaty, Reut. The Hebrew Universal Dependency Treebank: Past Present and Future. In Proceedings of the Second Workshop on Universal Dependencies (UDW 2018). Pages 133-143, 2018
Seker, Amit; More, Amir; Tsarfaty, Reut. Universal Morpho-syntactic Parsing and the Contribution of Lexica: Analyzing the ONLP Lab Submission to the CoNLL 2018 Shared Task. In Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. Pages 208-215, 2018
Amram, Adam; Ben-David, Anat; Tsarfaty, Reut. Representations and Architectures in Neural Sentiment Analysis for Morphologically Rich Languages: A Case Study from Modern Hebrew. In Proceedings of the 27th International Conference on Computational Linguistics. Pages 2242-2252, 2018
More, Amir; Çetinoğlu, Özlem; Çöltekin, Çağrı; Habash, Nizar; Sagot, Benoît; Seddah, Djamé; Taji, Dima; Tsarfaty, Reut. CoNLL-UL: Universal morphological lattices for Universal Dependency parsing. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), 2018
Tsarfaty, Reut. The Natural Language Programming (NLPRO) Project: Turning Text into Executable Code. In Proceedings of the REFSQ Workshops, 2018
More, Amir; Tsarfaty, Reut. Universal Joint Morph-Syntactic Processing: The Open University of Israel’s Submission to The CoNLL 2017 Shared Task. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. Pages 253-264, 2017
Cagan, Tomer; Frank, Stefan L; Tsarfaty, Reut. Data-driven broad-coverage grammars for opinionated natural language generation (ONLG). In Proceedings of the International Meeting of the Association for Computational Linguistics, 2017
More, Amir; Tsarfaty, Reut. Data-driven morphological analysis and disambiguation for morphologically rich languages and universal dependencies. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics. Pages 337-348, 2016
Nivre, Joakim; De Marneffe, Marie-Catherine; Ginter, Filip; Goldberg, Yoav; Hajic, Jan; Manning, Christopher D; McDonald, Ryan T; Petrov, Slav; Pyysalo, Sampo; Silveira, Natalia; Tsarfaty, Reut; Zeman, Dan. Universal Dependencies v1: A Multilingual Treebank Collection. In Proceedings of LREC. 2016
Tsarfaty, Reut; Pogrebezky, Ilia; Weiss, Guy; Natan, Yaarit; Szekely, Smadar; Harel, David. Semantic parsing using content and context: A case study from requirements elicitation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Pages 1296-1307, 2014
Seddah, Djamé; Kübler, Sandra; Tsarfaty, Reut. Introducing the SPMRL 2014 shared task on parsing morphologically-rich languages. In Proceedings of the First Joint Workshop on Statistical Parsing of Morphologically Rich Languages and Syntactic Analysis of Non-Canonical Languages. Pages 103-109, 2014
Cagan, Tomer; Frank, Stefan L; Tsarfaty, Reut. Generating subjective responses to opinionated articles in social media: an agenda-driven architecture and a turing-like test. In Proceedings of the Joint Workshop on Social Dynamics and Personal Attributes in Social Media, pages 58-67, 2014
Tsarfaty, Reut. Syntax and Parsing of Semitic Languages. Natural Language Processing of Semitic Languages, 67-128, 2014, Springer, Berlin, Heidelber
Stay in touch with us
Interested in hearing more? Drop us a note
Bar-Ilan University, bldg. 216
Room 002
reut.tsarfaty@biu.ac.il